什么是网站日志?网站日志分析的方法与步骤
时间:2022-08-07 09:50编辑:九州下载来源:www.wzjsgs.com
网站日志(服务器日志)是记录web服务器接收处理请求以及运行时错误等各种原始信息的以.log为后缀的日志文件。网站日志的用途主要有两种,其一是记录网站的运营情况,如用户IP、操作系统、访问页面、蜘蛛抓取情况等信息;其二是记录网站运营过程中发生的错误详情,如错误页面、错误代码等信息;专业的SEO人员能够通过查看网站日志了解搜索引擎网页蜘蛛爬行抓取网站的详细数据,从而做出利于SEO(搜索引擎优化)的调整。
通俗解释:打个简单的比方,网站日志就相当于飞机上面的黑匣子,当网站出现问题或需要查看网站各项数据的时候首先查看的就是网站日志。通过网站日志可以清楚的得知用户在什么IP地址、什么时候访问的、用的什么操作系统、通过哪个浏览器、显示器分辨率是多少、访问了你网站的哪个页面,做什么操作,是否访问成功等等信息。
网站原始日志不仅包括了用户的点击行为,同时也记录了搜索引擎抓取及停留等动作,下面就以实例来进行网站日志分析,这里针对百度。
第一步:下载网站日志
网站日志需要在服务器下载(通常以logs命名),不懂如何下载的朋友可以咨询技术人员(公司没有专门技术的话可以咨询服务器提供商),另外需要注意的是,有些服务器为了节约空间,没有设置保留网站日志。
第二步:用Notepad++打开日志文件
Notepad++有强大的编辑能力,安装也十分方便,大家可以自行搜索下载,下面是日志打开的截图,一些数据筛选提取将从这里开始。
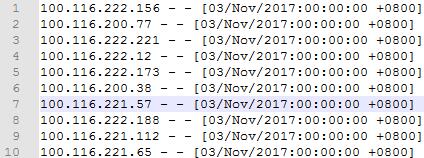
第三步:筛选出百度蜘蛛轨迹
百度蜘蛛是Baiduspider/2.0,所以我们按Ctrl+F调出查找功能,如图:
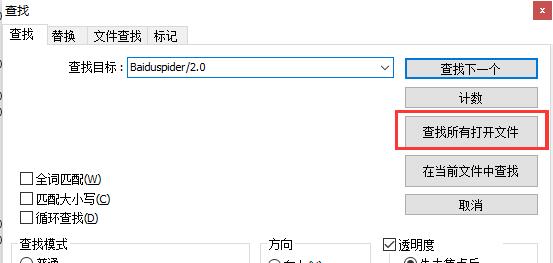
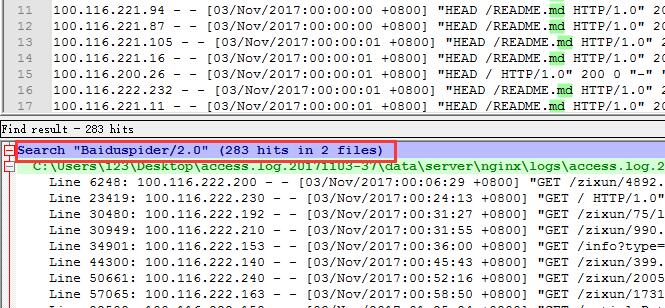
在查找目标量输入Baiduspider/2.0,最后点击“查找所有打开文件”,会在下方得出所有包含Baiduspider/2.0的行,如下图:
第四步:抽出页面url
1.先将所有查找出来的内容复制到另一个Notepad++窗口中,然后用两次扩展替换,如图:
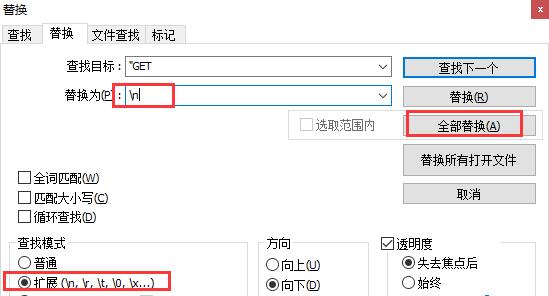
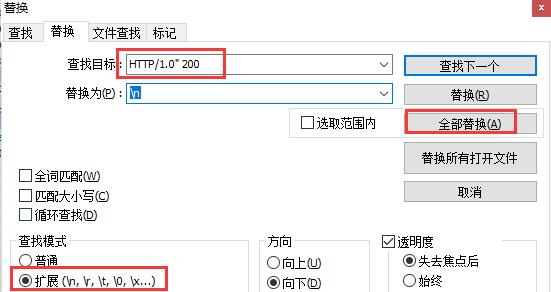
这里简单的说明,\\n是换行的意思,我们通过两次替换将页面的url剥离出来成为一行,然后将所有内容复制粘贴到表格(xls)中,如图:
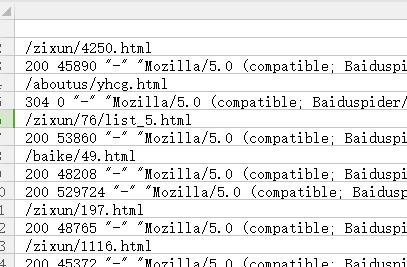
接着利用xls的自动筛选功能,筛选出页面url(看具体情况,一次筛选不成可进行多次筛选),如图:
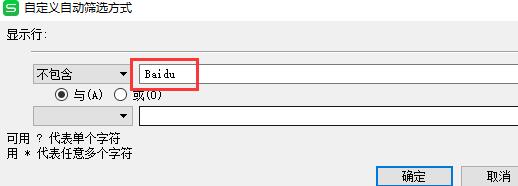
更多操作,比如说要看看tag页面被抓取了多少,我们可以筛选包含tag的页面,如图:
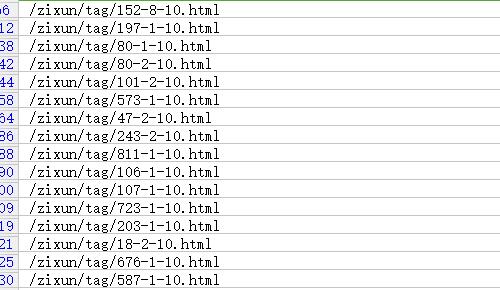
到这里大家应该知道网站日志分析的方法与步骤了,更多的细节分析大家可以根据具体的需求进行。另外,知道了哪些页面被抓取了,他们的收录又是怎样的呢?我们可以用Python来批量检测,如图:
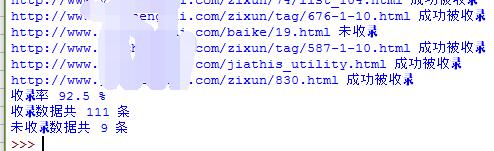
关于网站原始日志的分析(seo方向)就到这里,希望能对大家有所帮助。
相关文章
-

常见网络营销推广方法有哪些
1、搜索引擎营销 搜索引擎营销是目前最主要的网站推广营销手段之一,尤其基于自然搜索结果的搜索引擎推广,因为是免费的,因此受到众多中小网站的重视,搜索引擎营销方法也成为网络营销方法体系的主要组成部分。
2052-01-21 14:45 -

大数据营销平台有哪些?(国内八大数据营销平台)
大数据营销是指基于多平台的大量数据,依托大数据技术的基础上,应用于互联网广告行业的营销方式。大数据营销衍生于互联网行业,又作用于互联网行业。依托多平台的大数据采集,以及大数据技术的分析与预测能力,能够使广告更加有效,给品牌企业带来更高的投资回报率。
2023-03-24 11:02 -
网站采用静态网页的优缺点
小九在和不少从事SEO的朋友交流,在有关搜索引擎优化方法介绍时,总是强调静态网页对搜索引擎优化的重要性,那么静态网页的优点和缺点有哪些?
2023-03-18 11:17 -
WordPress插件实现出站链接添加Nofollow属性
博客是分享给大家看的,咱们都希望自己的博客有众多的fans,最直观的体现就是博客评论的多少,博客的留言者通常会将自己的博客名或网站名的网址链接,这是博客的一大特色,通过这种形式可以实现博主之间的互访,然而对于要进行seo优化的博客来
2023-03-18 11:16 -
外贸网站建设的注意事项
现在深圳互联网的网站建设有几个热门,外贸b2c的网站就是其中之一。深圳外贸企业建设网站时应该考虑到许多方面,自己的网络站点就是自己的门面,合格的企业网站会为你带来源源不断的客源,不成功的站点门可罗雀,所以,在进行外贸网站建设时,你要考虑
2023-03-18 11:15 -
五金行业网络推广
中国经济的持续高速发展以东莞为中心的华南制作业已成为中国加工制作业最发达最首要的组成部分,东莞长安镇则是该地区机械五金模具的生产中心和流通中心,在华南乃至全国都享有盛誉,先后被评为“广东省模具专业镇”、“东省产业集群升级
2023-03-18 11:14














